Interactive Reflexive Musical Systems, IRMS in short, were originally invented at the SONY FRANCE Computer Science Laboratory in Paris (Pachet 2004). The notion of IRMS emerged from experiments in novel forms of man-machine interactions, in which users essentially manipulates an “image” of themself. Traditional approaches in man-machine interactions consist in designing algorithms and interfaces that help the user solve a given, predefined task. Departing from these approaches IRMS are designed without a specific task in mind, but rather as intelligent “mirrors”. Interactions with the users are analysed by IRMS to build progressively a model of this user in a given domain (such as musical performance). The output of an IRMS is a mimetic response to a user interaction. Target objects (e.g. melodies) are eventually created as a side-effect of this interaction, rather than as direct products of a co-design by the user.
This idea took the form of a concrete project dealing with musical improvisation, The Continuator. The Continuator is able to interactively learn and reproduce music of “the same style” as a human playing the keyboard, and it is perceived as a stylistic musical mirror: the musical phrases generated by the system are similar but different from those played by the users. Technically, the Continuator is based on the integration of a machine-learning component specialized in learning and producing musical streams, in an interactive system. Many algorithms have been proposed to model musical style, from the early days of information theory of the 50s, to the works of David Cope (Cope 1996), who showed that a computer could generate new music “in the style” of virtually any known composer. However, these mimetic performances were the result of off-line processes, often involving human intervention, in particular for structuring musical pieces. The Continuator was the first system to propose a musical style learning algorithm in a purely interactive, real-time context (Pachet, 2003). In a typical session with the Continuator, a user freely plays musical phrases with a (Midi) keyboard, and the system produces an immediate answer, increasingly close to its musical style (see Figure 1). As the session develops, a dialogue takes place between the user and the machine, in which the user tries to “teach” the machine his/her musical language.

Figure 1.1 A simple melody (top staff) is continued by the Continuator in the same style
The architecture of IRMS is simple. It consists of three main input types, and produce one output (see Figure 1.2). The three main inputs correspond to the three sources of information exploited by the system:
- A Learning input. This is where data to be learned to build the progressive modelof the user comes from.
- A Real time input. This is what triggersthe output of the system.
- Contextual input. This is information provided to the system, to controlits production.
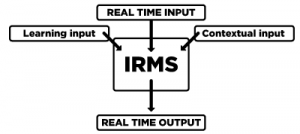
Figure 1.2. The global architecture of IRMS, with three inputs and one output.
This architecture allows the designer of IRMS to tailor the system to different “interaction modes”, and different users configurations (single, double, etc.). The machine-learning component of the Continuator is based on Markov models and is described (Pachet 2003). Based on the many experiments with the Continuator a number of characteristics emerged as being the most interesting to retain and generalize for developing other IRMS:
- Similarity or Mirroring effect. The IRMS produce musical samples that sound like those the user is able to produce. This similarity must be easily recognizable by the user, who experience the sensation of interacting with a copy of him/herself.
- The IRMS’s ability to reproduce the user’s personality is learned automatically and agnostically, i.e. without human intervention. In the case of the Continuator, for instance, no pre-programmed musical information is given to the system .
- Scaffolding of complexity. Because the user is constantly interpreting the output of the system, and altering his playing in response, it is important to consider the longer term behaviour of the user-machine interaction. Incremental learning ensures that the IRMS keep evolving and consequently that the user will interact with it for a long time. Each interaction with the system contributes to changing its future behaviour. Incremental learning is a way to endow the system with an organic feel, typical of open, natural systems, as opposed to pre-programmed, closed-world systems. This scaffolding of complexity implies in turn a number of technical constraints, such as the ability for the IRMS to store/retrieve models incrementally.
How IRMS will serve the purposes of the MIROR project
The success of the Continuator project was probably mostly due to this specific and novel combination of machine-learning and real-time interaction. Several experiments were conducted with professional musicians, notably Jazz improvisers (Pachet 2002) and composers such as György Kurtag (Desagnat 2002). The results were exciting, both from a technical viewpoint, but also from a psychological one. The idea to use the system in a pedagogical setting, with young children came naturally. A series of exploratory experiments were then conducted to evaluate the impact and the new possibilities offered by the system in a pedagogical context. The results were more than promising, triggering a whole series of studies aiming at further understanding the nature of musical reflexive interaction (Addessi and Pachet, 2005). However all these experiments were based on a constraint-free system, with no explicit pedagogical constraint implemented. A substantial part of the technical programme of the project will consist in extending this component in substantial ways, by integrating explicitly pedagogical constraints for using it in classroom settings. In a pedagogical context, other interaction modes will be developed, to take into account explicitly the role of the teacher, constraints coming from pedagogical goals, the possibility of making music with other children and the possibility of interacting through gesture. As described in Section 1.3 these extensions are non trivial technically, because of the properties of Markovian models, which by definition, are able to learn from input sequences, but not from external knowledge.
